Paper reading - Context Pruning and beyond hard pruning
引子
我们知道,在现在Agent需要处理的一大问题是长上下文下性能的开销问题,对此infra团队有非常多的优化,从attention架构的优化如各种windowed attention到kv的压缩重用如cacheblend和megicdec等都提出了一系列的解决方案,但有一个最本质的方法是:有没有可能直接减少上下文的长度(去掉不必要的上下文?) ,这就是Context Pruning的出发点。
而截止2025年8月,相关的方法已经发展了两三年了,大体上可以分成几个类别,本文会对此做一些简单的介绍和总结。
借用naver lab最新的相关论文里面的说法,现在的方法可以被一个四方格归纳:
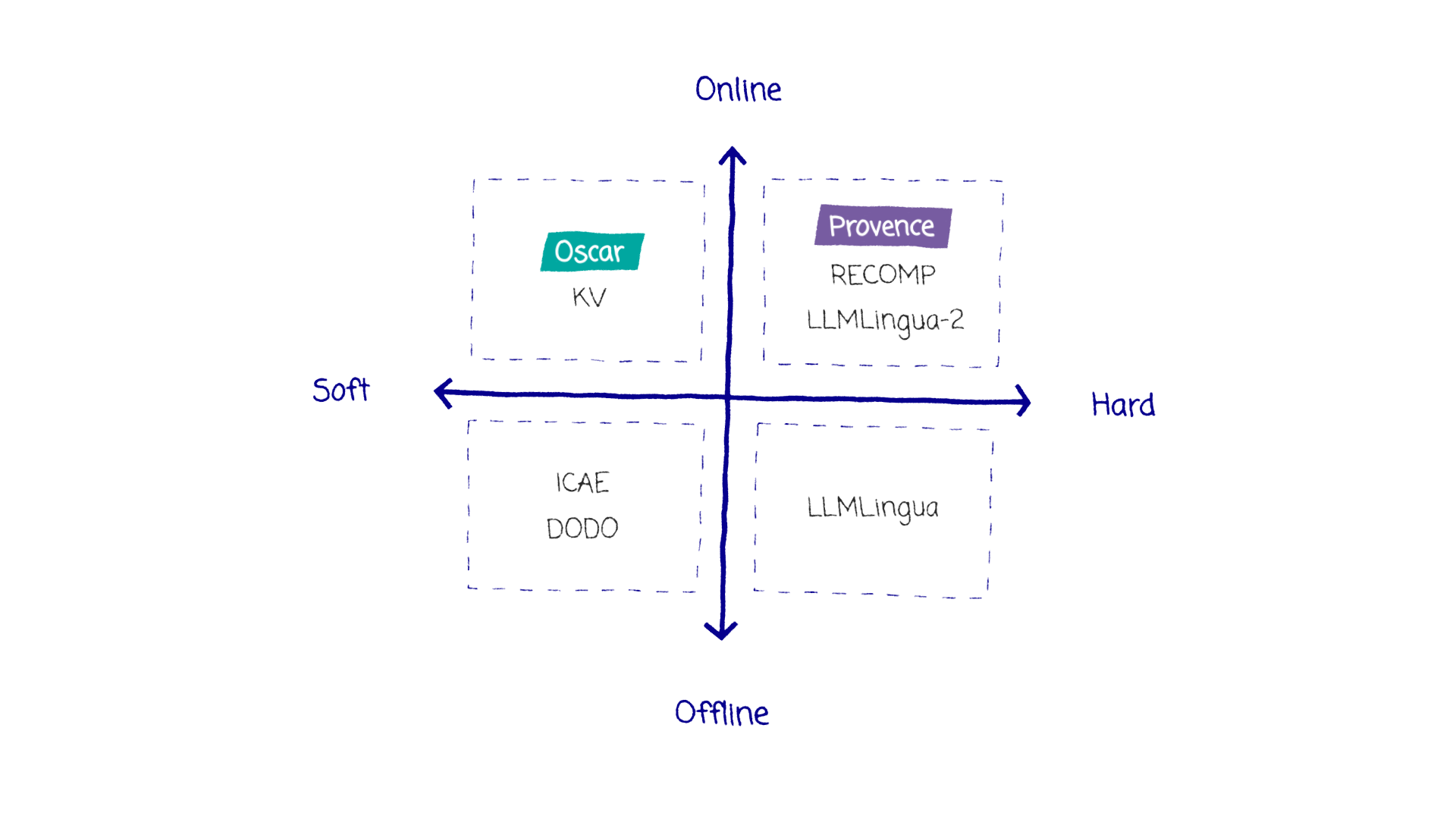
其中,Hard和Soft代表裁剪方法是直接作用于token上(hard,相当于裁剪结束后,输入的是一个新的prompt),还是作用于token的embedding上(soft,相当于裁剪结束后,输入的是一个新的qkv和其他东西,无法还原出“原始”的token输入)
在线和离线一般代表着这个裁剪方案是否依赖于用户查询q,依赖q的方案是在线的,不依赖q的方案是离线的,可以提前做好。但传统上,如果你的裁剪方法也需要用到和原始模型一样大的LLM,也一般称之为离线,或许“是否会对在线推理造成明显时延影响”做划分更好一些
离线硬裁剪
在最早期的时候,就有相关的一些朴素方法,例如直接对查询文本段做一次总结摘要,再用总结后的文本段去做后续的任务,这种方法是离线硬裁剪的典型代表。如果用的是llm就是离线的,如果用轻量级模型做摘要或者总结就是在线的
而在后面的时候,出现了例如微软的llmlingua这样的工作,直接用一个小模型(gpt2 small,llama-7b, etc)去预测哪些token是重要的,哪些token是不重要的,然后把不重要的token直接裁剪掉,这种方法也是离线硬裁剪的典型代表。(llmlingua2 换成了微调的 BERT 来做这个事情,所以可以说在线的), 其出发点和常规的硬裁剪可能有部分地方不同,例如llmlingua认为,裁剪本身是可以得到一些人类不可读但是大模型可以理解的token序列的,所以可解释性上可能并没有想象的那么强。
离线软裁剪
和硬裁剪同时推进的是软裁剪相关的工作,其想法很简单: 如果我牺牲解释性,直接调整prompt的embedding这类,即使产生的是不对应任何token的"fake embedding",其在高维空间中也应该融合了多个token的语义,理应得到更高的压缩率(可以理解为,在训练过程中为llm 扩充为无限词表,然后定义了一些高效的"额外语言")
比较早期的工作是 xRAG, 其裁剪策略非常极端,将整个段落都压缩成1个embedding X,怎么训练呢?一个在此类论文中经常出现的是重建loss,即
压缩前
压缩后, , 即自蒸馏,希望压缩后依然能重建原始的输出,论文实际中可能会用变体版本来实现指令遵循等
xRAG的做法是,使用一个通用编码器E,把这个编码器E视作一个新的模态,仿照CLIP的方法直接用MLP projector做通用编码器和实际使用的LLM token embedding的模态对齐
但[大家实测下来](笔记:RAG 的相关优化方法之六(xRAG/PISCO) - 刀刀宁的文章 - 知乎 https://zhuanlan.zhihu.com/p/29292925032),xRAG的效果并不好,而相对较好的是更新的Pisco方法
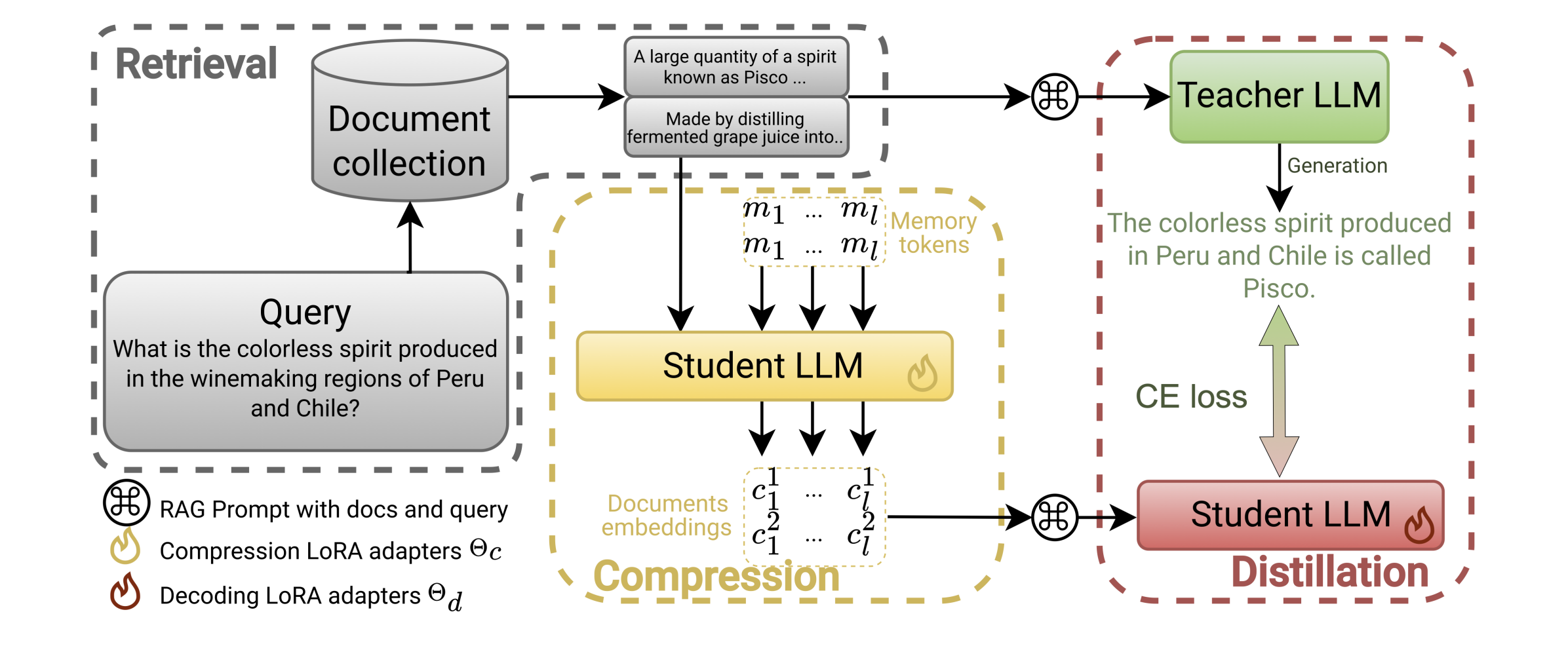
Pisco将检索到的文档D和memory tokens一起送到LLM中,产生embeddings
再将embeddings +query送到相同的LLM中,产生输出,这个 q+E 和原始的 q+D 比较, 计算交叉熵损失
这里有一些复杂的地方:
-
虽然叫解码和编码,但是Student LLM都是同一个LLM, 只是训练不同LoRA模块
-
交叉熵是怎么得出的? teacher模型和student模型都是采用的最大长度128的贪婪解码,就可以直接令 , 优化目标是 和 还有 memory_tokens
-
如何理解memory token? 我觉得文章是借用了之前的一些研究比如ICAE, 在这些文章之中,训练的压缩机制是,将上下文压缩成一个定长的memory slot, 这里的memory token实际上只是多个embedding向量而已,而更关键的是LoRA微调的,我的理解是,memory tokens只是一个后置的、可以看到Documents的所有信息(假设它没有魔改注意力)的语义位置,叫tokens也可以理解为直接扩了词表加入了l个特殊token,类似BERT里面的
[BOS],只是decoder llm需要后置。- 文章并没有细说这里的注意力是怎么设置的,但从后文中发现的memory tokens具有明显的位置特性(例如1位mem token主要注意最开头一段),感觉应该是没改过
-
文章的另一个重要的实验结论是,微调student llm()是必要的,之前的研究中没有相关模块,会导致性能的大幅度下降。这细想其实是一个很有趣的事情,可以注意到,压缩的时候是没有接触到query信息的(这也是为什么称为离线的原因),可以理解为某种意义上的LLM as an embedder,而加入了query和embedding再训练的时候,一边学会了如何理解自己产生的embedding,另一方面学会了如何根据query去选择embedding,整体上类似于ColBERT架构的Reranker(前面是multi-vec embed, 后面是maxsim)
在线硬裁剪
Provence
之前的裁剪方案只注重于“自然语言是有冗余的”,所以主要做的都是token-level的pruning,而provence则更注重实际一些,它发掘了一个问题是,其实现在RAG里面的 “Chunk” 是一个特别微妙的概念
如果chunk切得大了,那上下文自然就长了,甚至效果也会明显下降(详见ground truth在chunk中的不同位置的position bias相关的研究,现有embedder对这个bias耐受性不佳,会狠狠掉点);但如果chunk切得小了,语义信息的丢失、检索的困难又是很恼人的事情(先不论检索,检索到了多个小块之后信息不够怎么办?一种是合并,但策略怎么定?另一种是Anthropic的Contextual Retrieval,把上下文放进来,本质上还是变成大块(我说这个a一串真是炒作勾啊.jpg))。
而Provence给了一个折中的方案,既然我们有句子级别的语义,为什么不用呢?分几步走
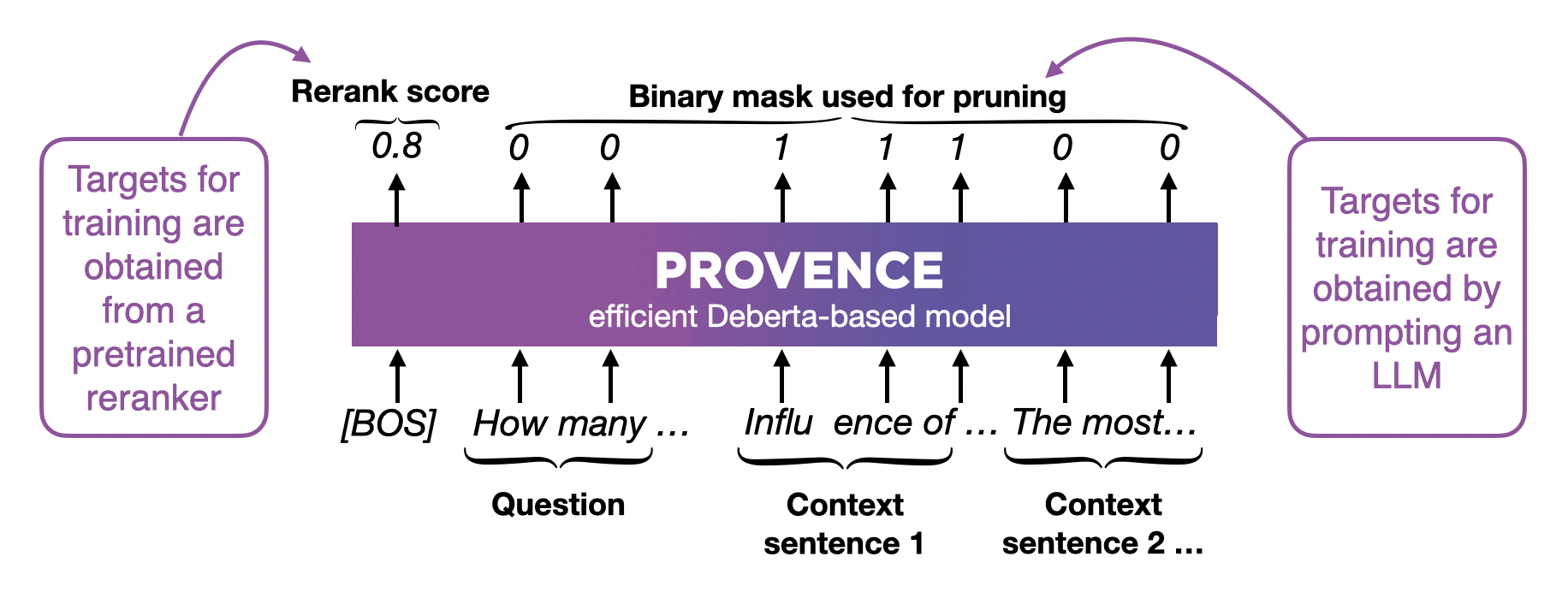
- 训练一个接受q,d的BERT,给每一个token打0~1分,并根据用户指定的阈值进行二值化变为0/1, 表示删除/留下
- 进行句子级别的聚类,裁剪掉0的token数量大于1的token数量的句子
如何训练呢?选取有5~10个句子的段(可以多次选取来拓展到更长的上下文),标上句子序号,让LLM选择相关句子来产生label,从而训练模型
这里其实做了很有意思的工程设计,
-
如果让LLM来打token-level的标,肯定是收集不到足够的样本的,并且真的无所谓多出来的几个token,更在意句意的完整性
-
BERT带来了相当多的好处:
-
这样进行的句子裁剪,每个句子都可以和整个chunk里面的所有上下文交互,使得一个句子的保留与否不仅取决于这个句子和查询的相关性,还取决于其于其他(和查询相关性高的)句子的相关性,这就使得这个方法必然会优于按句子切分的朴素方法
-
我们的 reranker 也就是个BERT啊,完全可以训裁剪和训rerank一起进行,推的时候也一样,相当于和rerank overlap了
-
在线软裁剪
Oscar
Pisco为代表的离线软裁剪有一个问题是,它的压缩需要微调,并且受限于难以对齐encoder-only架构的预训练编码器模态和实际推理使用的decoder LLM的模态,难以把压缩这一步在线做
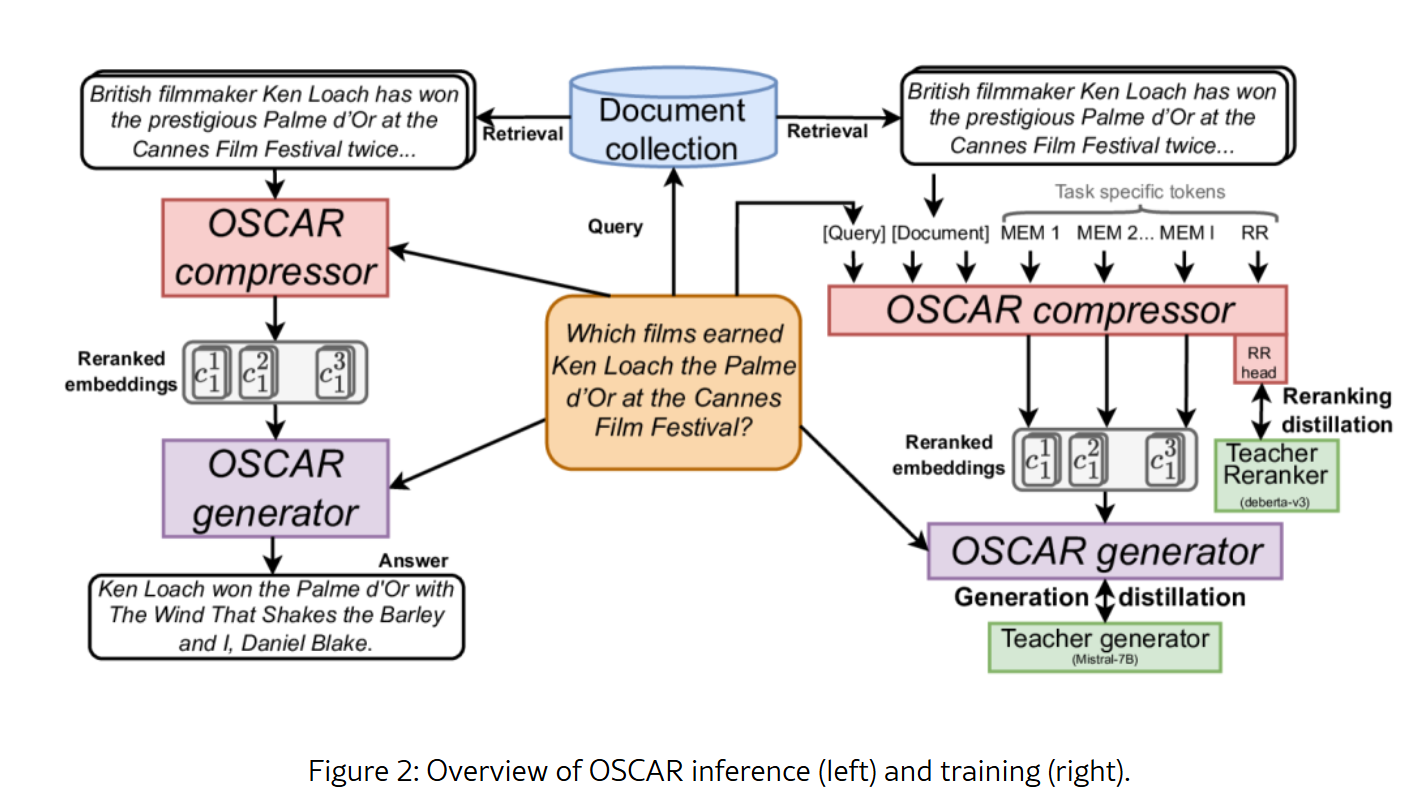
Oscar就提出了一种方法是,我的对齐既然难做,我直接不对齐了,使用LLM的前L层 + memory token(他们也做了用Llama硬对齐的版本),足以得到够好的embedding,文章最大的贡献其实是实验证明了这样表达能力已经足够,能训出来(太神奇了LLM)。当然,L越大效果越好
而还是复用Provence的工程技巧,把裁剪和rerank overlap起来,OSCAR的compressor留了一个RR头,在这个头和Teacher Reranker对齐,整体的Loss就是rerank loss + generation loss
而令LLM理解embedding这件事情还是通过LoRA adapter来做,这篇文章其实像是序列工作的延申,综合了PISCO的训练方法,把PISCO的压缩部分从LLM + LoRA换成目标模型的前N层transformer,然后压缩器全参微调、生成器LoRA微调,再使用和Provence相同的技巧进行rerank的overlap
异曲同工
从HyDE到“投机解码”
另一个有趣的工作是广义上的“裁剪”,或者就是更好的搜索吧。我们知道HyDE的思想是原始query一般都比较短,而生成的假设文档可能会更好地与索引文档对齐,所以使用 q‘ = q + generated d 来进行搜索。
而智谱的memorag 则提出了这样一种场景,我们是否能以低成本训练一个小模型,来根据源文本生成这个假设答案呢?(例如,使用Llama3-8B在哈利波特上训练比用Deepseek-R1在哈利波特上训练成本要低廉的多,将HyDE的生成方从R1自己换成小模型)这就非常像是投机解码的思想了
外接模块: memory decoder, catridges
其实这种将memory训为embedding的方法确实不少,如果说前面的压缩器是在训一个meta network,能够从doc生成embedding的话,外接模块的工作就是在训练embedding本身 -> 我能否直接从一个大的文档库中训练出一个参数化的memory?
最近的memory decoder选择的是直接扭曲生成过程,将一个小模型在目标适配数据集上训练,在大模型生成token时,将小模型的概率和大模型的概率相加(再重归一化),认为这样会带来领域知识的纠正(比较暴力www)
而另一篇catridges 则是在使用类似P-tuning的方式训一个Prefix KVCache,在推理时实时加载,而希望这个KV中有相关的memory
包括一系列的kvcache evict的工作也是在做类似的东西,为了决定evict哪些甚至都把搜索又搬上来了,比如clusterKV的knn(笑)
总结
总体而言,我感觉相关工作已经进入了��深水区了,硬裁剪可能在某些程度上到头了,现在主流在探索一些牺牲解释性的,更能scale out的方法来进行参数化memory来解决长上下文、领域适配等一系列问题
而大家方法逐渐趋向于无标签学习的统一也再次证明了scale out能力在广义embedding能力的训练上的重要性
另一个很有意思的是,可以看到搜索中的多向量和多memory token有一些很有趣的相似性,或许在后续的一些工作中,我们能看到一些多向量的方法被用到memory之中,希望会让memory这个很多时候靠prompt编故事的领域更多可验证性吧
而从另一个方面,正如这里列出的部分文章说的,自从eagle在投机解码中得到了确实很好的效果之后,大家都开始用 token + embedding的混合来捕捉更强的信息了,还有HyDE和投机解码这种很有趣的对应